
こんにちは、Einarです。

好きなキャラクターに特定のポーズを取らせたいのに、AIくんがまったく言うことを聞いてくれない――そんな経験、ありませんか?特にSD1.5時代では、こうした問題によく直面したはずです。例えば、武器を含む物を持たせたり、複雑な動きのあるポーズを取らせたり、あるいはAIが手足の位置を正しく認識できないせいで、シンプルなポーズですら破綻することがありました。
アイテムに至っては、気づけば「これは一体…?」と首をかしげるような謎の物体が出来上がってしまうことも…。
正直なところ、SDXLやIllustrious / NoobAI-XL系のモデルでだいぶ改善されましたが、それでもまだまだ根気が必要な場面は少なくありません(武志さんの剣をまともに生成させるために、何度発狂しそうになったことか…)。
しかし、幸いなことに、ここ数年でこうした問題を解決する手段がいくつか登場しました。ただ、意外とその存在を知らない人も多いようなので、今回はその中でも最もよく使われている「ControlNet」について解説することにしました!
Controlって何? #

…ちょっと詠子さん、説明が過激すぎません? まあ、言いたいことは合ってるんですが。
その名の通り、ControlNetとは「モデルの生成を特定の方向にコントロールする」ための仕組みです。これは、特別に作られた「入力画像」(詳しくは後述)と追加のモデルを組み合わせて使用し、生成結果に影響を与えるものです(どれくらい影響させるかはユーザー次第)。例えば、キャラクターのポーズを指定したり、キャラクターや物体、人が画面内でどの距離感にいるかを指定することもできます。さらに、t2iだけでなく、i2iのワークフローでも活用可能です。

この手法はスタンフォード大学で約2年前に発表され)、すぐにA1111やその他のWebUIに実装されました。その後も発展を続け、現在ではSDXLやIllustrious、NoobAI-XL、Fluxといったモデル向けのバリエーションも登場しています。
すごいですよね?実際、めちゃくちゃ便利です! 唯一のデメリットは、追加のモデルを読み込むためVRAMの使用量が増えること、そして計算量が増えるため生成に時間がかかること。でも、それを差し引いても使いこなせば頼れる救世主になりますよ!
難しい選択 #

でも実際、ControlNetで何ができるの? それが、もう本当に色々ありすぎるんです!
先ほども書いた通り、ControlNetには様々なモデルが存在し、それぞれ異なる目的のために作られています。モデルごとに必要な入力画像の形式が違い、また、画像生成に与える影響の強さも異なります。全てを挙げるとキリがないですが、代表的なものをいくつか紹介しましょう。
- openpose: 人体を棒人間のような構造で表現し、キャラクターのポーズを正確に指定できるモデル(指の位置まで調整可能)
- depth: 「深度マップ」を使い、シーン内のキャラクターや物体がどの程度遠いか・近いかを判別し、正しく配置できるようにするモデル
- canny: 物体やキャラクターの外郭線(アウトライン)のみを抽出し、それを元に画像を生成するモデル。ネックレスや建物、人物の形状を厳密に表現したいときに活躍する
- lineart: 一見cannyと似ているが、こちらはアニメやリアル系の「線画」を活かして生成をコントロールするモデル
- tile: 入力画像を必要とせず、画像をタイル状に分割しつつ高解像度にアップスケールし、ディテールを向上させるモデル
- reference: 入力画像の描画スタイルや構図を別の画像に適用できるモデル
…と、このように選択肢が多すぎて迷ってしまうほどです!
このチュートリアルでは、特にポーズや構図に影響を与えるopenpose、depth、canny、lineartの4つに焦点を当てて解説します。他のモデルは主に画像のクオリティを向上させる用途ですが、今回はポーズや構図を制御する方法に重点を置いているため、この4つを中心に進めていきます!(というか、私が一番使い慣れているものでもあります!)
注意事項 #
このチュートリアルでは SD.Nextを使用しており、スクリーンショットもそのUIに基づいています。ただし、Stable Diffusionを使用するほぼ全てのUIでControlNetは利用可能です。
各UIごとの導入・使用方法については、以下のガイドを参考にしてください:
- A1111: https://highreso.jp/edgehub/stablediffusion/controlnet.html
- ComfyUI: https://note.com/aicu/n/n151f019bcc92
入力画像の作成 #

でも、その素晴らしいポーズをControlNetで実現する前に、まずは元となる入力画像を用意する必要があります。たとえば、武志さんの「ブレードチャージ」の構えのようなポーズを作りたいなら、それに近い写真やイラストを準備しましょう。できれば、生成したい画像のアスペクト比に近いものを選ぶのが理想です(もしくは、あらかじめ用意されたポーズを使う手もあります)。
もう一つの選択肢として、自分でポーズを作る方法もあります。PoseMyArtのようなサービスを使えば、3Dマネキンを動かして簡単にポーズを作成できます。また、CLIP STUDIO PAINT PROやEXを持っているなら、3DモデルやCLIP STUDIO ASSETSにある豊富なポーズを活用し、自分だけのオリジナルポーズを作ることも可能です。
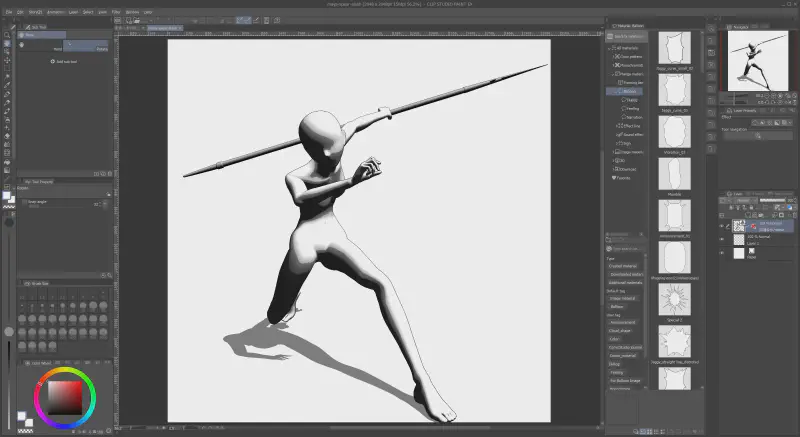
そして、ポーズが決まったら、そこから実際の入力画像を生成する方法はいくつかあります。
解決策A: ネット上の既製ポーズを利用する #
これは、一から始める場合に最も簡単な方法です。Civitaiなどのサイトには、さまざまな形式のポーズ画像が豊富に用意されており、ダウンロードすればすぐに使えます。さらに、これらは単なるPNG画像なので、特別なソフトウェアを用意する必要もありません。
ただし、選べるポーズの種類には限りがあり、自分が求めるものと完全に一致するとは限らないというデメリットもあります。それでも、手軽に使える方法としては最適なので、まず試してみる価値は十分にあります!
- https://a-lgil.github.io/pose-depot/gallery/
- https://openposes.com/
- https://civitai.com/search/models?modelType=Poses&sortBy=models_v9&query=pose
解決策B: ControlNetで入力画像を作成する #
実は、ControlNet自体にも、手持ちの画像から入力画像を作成する機能が搭載されています。どのUIを使用していても、ControlNetには「プリプロセッサ」と呼ばれるツールが用意されており、生成時に自動で入力画像を作成することも可能です。
用途に応じて、適切なプリプロセッサを選択する必要があります。例えば、以下のような選択肢があります(UIによって名称が若干異なる場合があります):
- openpose:DWpose
- depth:DepthAnything
- canny:Canny
- lineart:LineartまたはLineart Anime
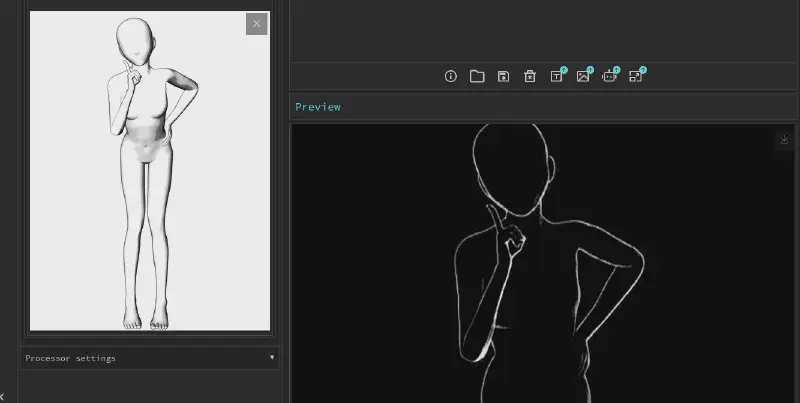
これらの機能を活用すれば、ポーズ作成の手間を大幅に省くことができ、とても便利です。ただし、プリプロセッサを使用するには追加のモデルが必要になるため、VRAMの使用量が増える点には注意が必要です。また、一部のプリプロセッサは低解像度のデータで学習されているため、期待した結果が得られない場合もあります。特に A1111では、プリプロセッサの解像度を調整できますが、その分VRAMの負荷も増えるので気をつけましょう。
解決策C: 自分で入力画像を作成する #
一部のプリプロセッサは、必ずしも完璧な入力画像を生成できるわけではありません。そのため、より正確なポーズや構図を再現したい場合は、自分で入力画像を作成するのがベストな選択肢となります。作成方法は入力の種類によって異なりますが、いくつかの手段があります。
Openpose #
CLIP STUDIO PAINT PRO/EX を使用している場合は、このマネキン をダウンロードし、自由にポーズを作成できます。また、PoseMyArt では、作成したポーズを Openpose 用のフォーマットでエクスポート可能です。
さらに、A1111拡張機能に組み込まれている Openpose Editor もありますが、現在は正常に機能していないため、使用は推奨しません(解像度が正しく保存されない不具合が長期間放置されています)。ComfyUIの類似ツール も存在しますが、こちらの動作については未確認です。
Depth #
HuggingFaceのDepth Anythingを利用すれば、手軽に深度マップを作成できます。ただし、ダウンロードする際は必ず「グレースケール」の画像を選択し、カラーマップの方を選ばないように注意してください(詳細はスクリーンショット参照)。

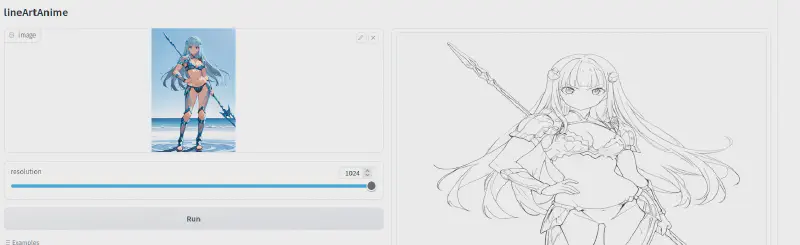
Canny/Lineart #
また、HuggingFace には、例えば このサービス など、CannyやLineart変換ができるツールがいくつかあります。変換後のプレビューが歪んで見えることがありますが、ダウンロードすれば正しい比率の画像が得られるので安心してください。
最初の画像を生成しよう #

このチュートリアルでは、過去に公開したポーズの一つを使用します。自分で試してみたい場合は、こちら からダウンロードできます。シンプルな実験として、今回はOpenposeを使ったものとDepthを使ったもの、2種類の画像を作成します。
ただし、生成を始める前に注意すべき点があります。特にSDXLでは多くの異なるControlNetモデルが存在し、どれを選べばいいのか分かりづらいです。以下の選択肢を参考にしてください。
- SD 1.5 を使用している場合は、ControlNet 1.1 モデル が基本的に問題なく使えます。
- SDXL またはその派生モデル(Animagineなど)を使用している場合は、xinsirさんのモデル をおすすめします。他のモデルよりも高品質です。
- NoobAI-XLやIllustriousを使っている場合は、NoobAI-XL用のコレクション または Illustrious用のコレクション を選びましょう。(IllustriousにはOpenposeがないようですが、NoobAI-XL版を試すのもアリかもしれません)。
- Pony Diffusionを使っている場合… すみません、詳しくないので信頼できるモデルがあるのか分かりません!
使用するUIによっては、これらのモデルを事前にダウンロードする必要があります。あるいは、UIが自動でダウンロードしてくれる場合もあります。詳細は記事冒頭のリソースリンクを確認してください。(SD.Nextでは選択した時点で自動ダウンロードされます)。
さあ、準備は整った? …いや、もう少しだけ注意点があります!
強さの問題 #

ControlNetを使用する際には、どれくらい強く影響を与えるか を設定する必要があります。この値は 0(0%)から1(100%) の範囲で調整可能です。
しかし、強ければ強いほど良いというわけではありません。例えば、SD 1.5のDepthモデル は影響が強すぎるため、背景が消えてしまったり、キャラクターが… なんというか、あまり健全ではない見た目になってしまうこともあります(汗)。正解となる数値は存在しませんが、以下のような 経験則 があります。
- Openpose モデルは基本的に1で問題なし。
- Depthモデル はほとんどのモデルに対して強力すぎるため、0.4〜0.5を推奨。
- Canny はSD1.5では強すぎる(最大0.5推奨)が、SDXLではむしろ弱い(0.7〜0.8までOK)。
- Lineart は1でも大きな問題は起こらない。
もちろん、これらはあくまで目安なので、実際に試しながら調整するのがベストです!
さあ、今度こそ本当に準備完了ですね!
生成の時間! #
まずは、まやちゃんが変身前によくとるポーズを生成してみましょう。使用するUIに画像を読み込み(ここでは SD.Next を使用)、自分の使用するAIイラストモデルに合ったControlNetモデルを設定します。
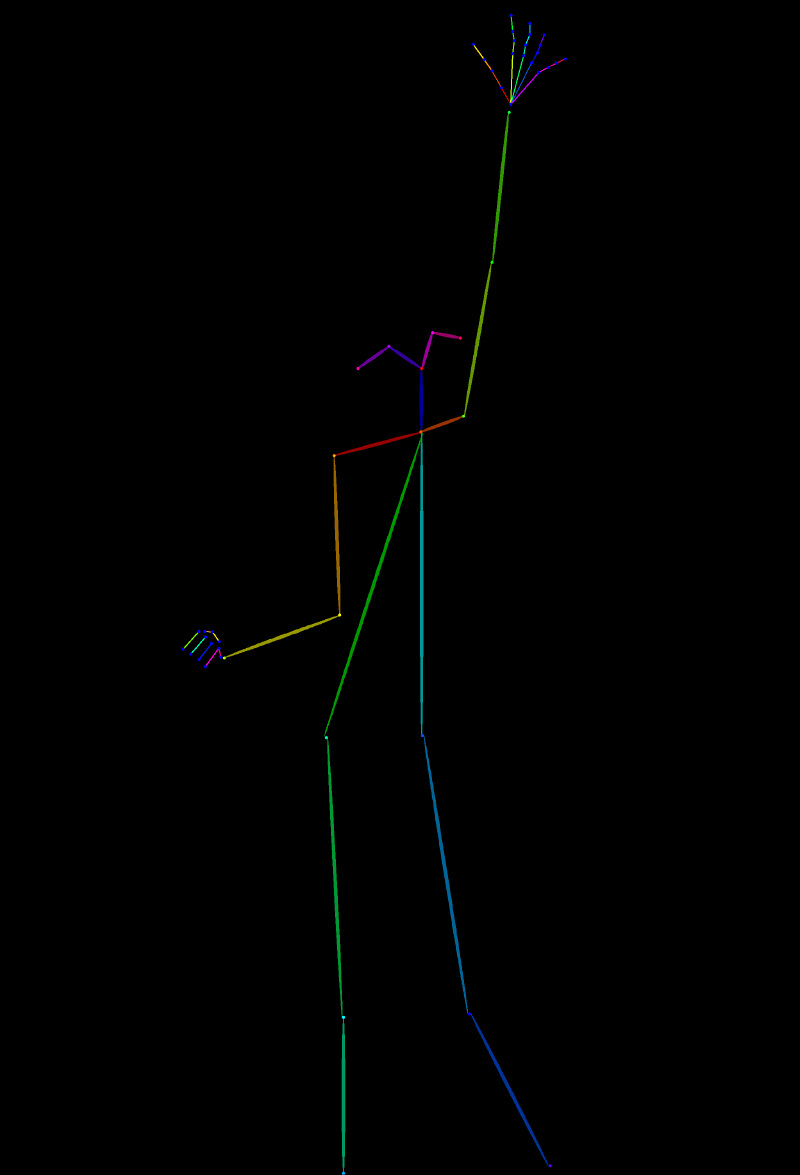
- SD 1.5:
control_v11p_sd15_openpose(またはfp16対応モデル) - SDXL:
xinsir-openpose - NoobAI(本記事で使用):
NoobAI-XL openpose
次に、プリプロセッサをnoneに設定し、強度を 0.9〜1.1 に調整します。SDXLやNoobAIを使用する場合、必要に応じて1.2まで上げることも可能です。今回は copycat-RouWei(レビュー記事はこちら)とNoobAI-XL Openposeを使用します。
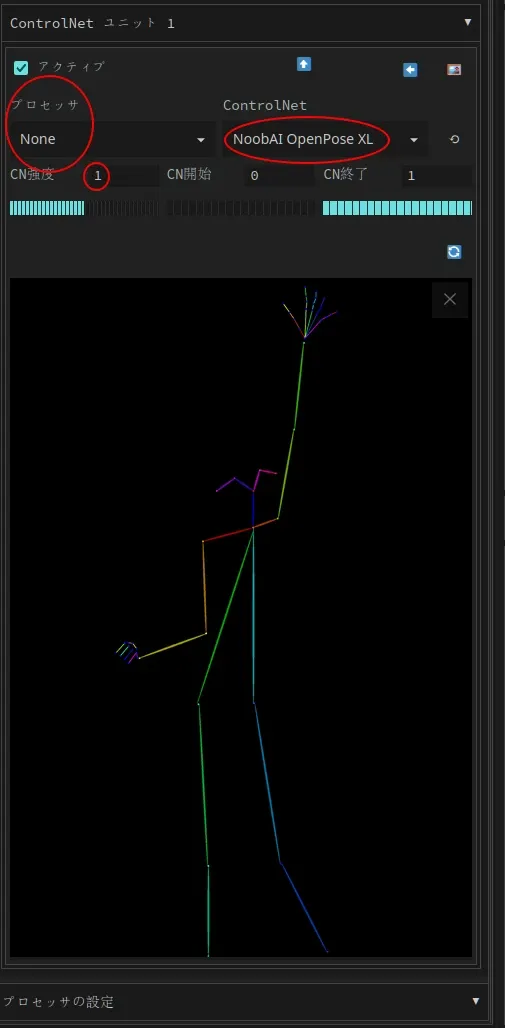
続いて、以下のプロンプトを使用します(モデルによって適宜調整してください)。
1girl, medium breasts, standing, full body, open hands, arm up, clenched hand, arm at side, armor, (white background:1.2), simple background, anime coloring, recent, masterpiece, best quality, absurdres, very aesthetic
ネガティブプロンプトも以下を使用します(こちらも、使用するモデルに応じて変更してください)。
lowres, (worst quality, bad quality:1.0), bad anatomy, bad hands, fewer digits, extra digits, sketch, signature, watermark, lipgloss, parted bangs, colored inner hair, blush, empty eyes, (dimple:1.3), (nose:0.85), lips, oldest, old, realistic, 3d, huge breasts, fangs,ai-generated, waving

じゃじゃ〜ん!彼女のポーズが、使用したスティックフィギュアにかなり近い形で生成されました!
モデルやポーズによっては、適切なポーズを得るのが簡単な場合もあれば、特に一部のSD1.5やSDXLモデルでは難しくなることもあります。こうした場合、ポーズに関連するタグを適切に設定する ことで、モデルを意図するポーズへと誘導しやすくなります。
では、別の入力方法を試してみましょう!Civitaiのこのポーズ を使用し転びそうな女の子の深度画像を取得します(かわいそうに…)。 今回は、前回と同様の手順で「depth」モデルを使用します。

- SD 1.5:
control_v11f1p_sd15_depth(またはfp16対応モデル)0.4~0.6 の強度で使用 - SDXL:
xinsir-depthを 0.6~0.8 の強度で使用 - NoobAI(本記事で使用):
NoobAI-XL depthを 1.0 の強度で使用
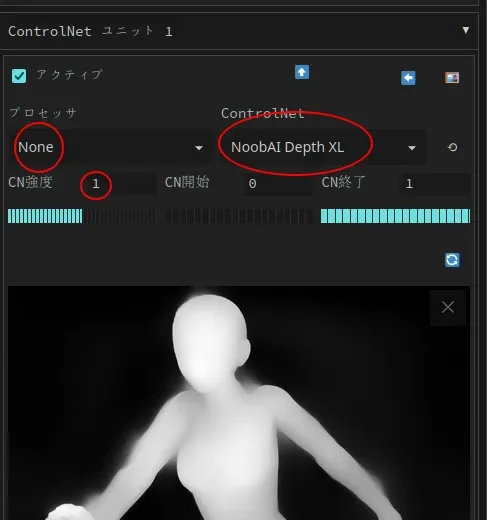
生成結果が入力画像にあまりにも近すぎる場合は、強度を下げて再試行すると改善されることがあります。
以下のプロンプトを使用して生成を行います。
1girl, original, solo, (from side), medium breasts, surprised, screaming, open mouth, full body, tripping, falling, leg up, outstretched arm, bikini, cleavage, navel, groin, linea alba, (white background:1.2), simple background, anime coloring, recent, masterpiece, best quality, absurdres, very aesthetic
ネガティブプロンプトはこちら。
lowres, (worst quality, bad quality:1.0), bad anatomy, bad hands, fewer digits, extra digits, sketch, signature, watermark, lipgloss, parted bangs, colored inner hair, blush, empty eyes, (dimple:1.3), (nose:0.85), lips, oldest, old, realistic, 3d, huge breasts, fangs,ai-generated, straight-on

そしてこちらが生成結果!この画像を見て気づいたかもしれませんが、ポーズが完全には入力画像と一致していません。 これは深度モデルの特性であり、特に奥行きや空間の関係を明確にする際に便利です。たとえば、カフェの内装写真を使って空間の奥行きを再現するなど、複雑なシーンを作成するのにも活用できます。
最後に、ラインアートを試してみましょう。今回は、私が作成したこのポーズ を使用します。槍を構えてパリィするポーズですが、当時ラインアート版を作成していなかったため、lineart anime のプリプロセッサを使って画像を作成しました。こちらから 事前処理済みの画像をダウンロードできます。このテストでは、すべてのモデルで 1.0 の強度を設定して問題ありません。
{kind=link}

- SD 1.5**:
/control_v11p_sd15_lineart(またはfp16対応モデル) - SDXL**:
xinsir-lineart-anime - NoobAI(本記事で使用)**:
NoobAI-XL lineart anime
では、以下のプロンプトを使用して生成してみます。(一部のモデルでは健全ではない結果になる可能性があるので注意してください)
1girl, original, solo, medium breasts, holding polearm, holding weapon, clenched teeth, parrying, hands up, (torn clothes), armor, , navel, (white background:1.2), simple background, anime coloring, recent, masterpiece, best quality, absurdres, very aesthetic
ネガティブプロンプトはこちら。
lowres, (worst quality, bad quality:1.0), bad anatomy, bad hands, fewer digits, extra digits, sketch, signature, watermark, lipgloss, parted bangs, colored inner hair, blush, empty eyes, (dimple:1.3), (nose:0.85), lips, oldest, old, realistic, 3d, huge breasts, fangs,ai-generated, straight-on

そして…完成!ラインアートに非常に忠実な画像が生成されました。よりモデルに自由度を与えたい場合は、強度を下げて試してみましょう。
これらの例からも分かるように、適切な入力画像を用意できれば、生成AIモデルでは難しいポーズでも比較的簡単に作成可能です。さらに、ControlNetは リージョナルプロンプティングにも対応しているため、キャラクター同士の相互作用をより細かく指定することもできます。通常のモデルで90%のケースは問題なく生成できますが、ControlNetを活用すれば、残りの10%もカバー可能です(その代償としてVRAM使用量や生成時間は増えますが…)。
さて…まさかこれで終わりだと思っていませんよね?
複数のControlNetモデルを組み合わせる #

ControlNetの便利な点のひとつは、十分なVRAMがあれば複数の入力画像を同時に使用できることです。これを活用することで、画像生成の条件をさらに細かく設定することができます。例えば、武器や持ち物の表現です。 NoobAIやIllustriousではかなり改善されたとはいえ、他のモデルではまだまだ苦戦することが多く、時には「これ何…?」というような形状になってしまうこともあります。
この問題を解決する方法のひとつがControlNetの複数適用です。例えば、Openposeを使ってポーズを指定し、Lineartを使って手の形と持ち物を指定することで、より正確にアイテムを描画できます。ただし、Lineartを適用する際には、手とアイテム以外の部分を消去することがポイントです。Lineartモデルはスタイルや構図への影響が比較的弱いため、最終的なイラストの印象を大きく変えることなく活用できます。また、多くのモデルではLineartだけではポーズを正しく認識できないため、Openposeを併用することで精度を高めることができます。
今回は、短編ストーリー「変身!水の戦士」の一場面で、槍を構えて戦うまやちゃんのイラストを作成してみます。まずはOpenpose画像とLineart画像をダウンロード(または下のギャラリーから保存)してください。使用するWeb UIでControlNetのユニットを2つ有効に設定します(A1111ユーザーは拡張機能の設定でユニット数の上限を調整する必要があるかもしれません)。今回の生成を完全に再現したい場合は、copycat-RouWeiとまやちゃんのLoRAを使用します。ControlNetの強度は、Openpose画像を1.05、Lineart画像を1.2に設定してください。 さらに、まやちゃんのLoRAを0.8の強度で適用し、以下のプロンプトを使用します。


(画像をクリックすると拡大表示できます)
1girl, original, solo, mayaalt, standing, (incoming attack), (slashing), looking at viewer, holding weapon, holding polearm, spear, ice spear, standing on liquid, full body, athletic, very long hair, (light blue hair:1.05), blue eyes, blunt bangs, serious, determined, v-shaped eyebrows, confident, open mouth, shouting, mizunosenshi, armor, cleavage, bikini armor, ice, ice armor, ice vambraces, ice leg armor, transparent armor, navel, groin, ice hair ornament, ice cuisses, hairpin, ice hairpin, floating hair, waves, blue sky, horizon, ocean, hdr, dramatic lighting, cinematic angle, cinematic lighting, anime coloring, recent, masterpiece, best quality, absurdres, very aesthetic
そしてネガティブプロンプト:
lowres, (worst quality, bad quality:1.0), bad anatomy, bad hands, fewer digits, extra digits, sketch, signature, watermark, lipgloss, parted bangs, colored inner hair, blush, empty eyes, (dimple:1.3), (nose:0.85), lips, oldest, old, realistic, 3d, (child, loli:1.2), huge breasts, fangs,ai-generated, knight, cape, capelet, dawn, sunrise, sunset, dusk, white hair, violet hair, dual wielding, iceberg, crystal, night, sand, dutch angle, beach, sword
生成を終えると、こんな感じの画像ができるはずです:

なかなかいい感じでしょう? VRAMに余裕があるなら、さらに多くのControlNetモデルを組み合わせて、画像をより細かく調整することも可能です(ただし、生成時間が大幅に増える点には注意してください)。今回は、Lineartの強度を高めることで、手や武器の形状が変わらないようにしています。この方法を応用すれば、武器だけでなく、手足の位置をしっかり固定したい場合にも活用できます。非常に便利ですね!
最後に #
今回のチュートリアルはここまでです。最後まで読んでいただき、ありがとうございました!(長かったですね!)ControlNetの活用方法については、まだまだ奥が深いですが、今回の内容が少しでも試してみるきっかけになれば嬉しいです。設定は少し面倒ですが、その価値は十分にあります!もしこの内容が役に立った、または「こんなチュートリアルが見たい!」というリクエストがあれば、ぜひXで教えてください!
それでは、また次回!
Einarでした。